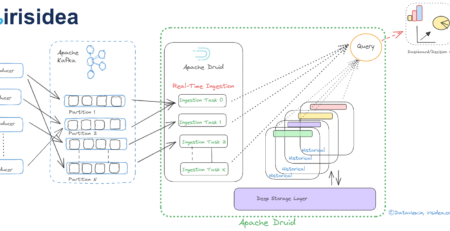
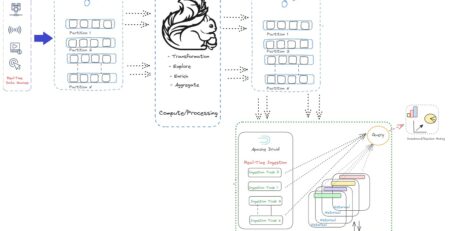
Establishment of Data Lake specific to multi-channel e-commerce application to understand customer’s buying pattern
Post order fulfillment data is becoming a very important asset of e-commerce vendors to understand complete buying pattern of customers. Especially for the e-commerce vendors who sells multiple products starting from electronics to apparels. Extraction and transformation are time-consuming operations when partially structured data starts moving from the various sources and finally land into the relational data warehouse. Data extracted from the social media are semi-structured (JSON or XML). As an example, Facebook provides information in JSON format through Graph API and same for Twitter streaming too. Besides, social media, we have another network like Bazaarvoice that connects brands and retailers to the authentic voices of people where they shop. To accommodate the data extracted from the former , another parsing operation has to be carried out to the shape of the data into a tabular form (row, column)before loading into a data warehouse for analysis.
Data generation and subsequently propagation from the social media is continuous and can be referred to as Streaming data. With available traditional data storage system, we are a handicap to store that massive volume of data due to disk/storage space scarcity. Even though e-commerce sites have multiple channels like web, mobile along with teleshopping etc., it’s straightforward to pull out the order placed data from the e-commerce database because data are already stored in the row-column format. Analyzing customer’s order placed data is not sufficient to understand the complete buying pattern.
Now a day’s customer’s rating and review data on the product detail page have started playing as deciding factor to add into the shopping cart and eventually place the order or not. Customer/online buyer have various option to choose right product by accumulating data from social media, n numbers of blogs, email etc. Interestingly data belongs to email, blogs are unstructured. This is also an another influencing factor for the customer to choose the right product. It’s a tough challenge to convert data into a common format and analysis on top of it. The key points or expected depth received after intricate analysis of entire captured data in the data lake helps in taking a strong business strategic decision to boost revenue growth. With available traditional RDBMS data warehousing system, the entire process is expensive and time-consuming w.r.t ETL and there will be an uncertainty whether we can achieve the goal or not.
Using Hadoop and its eco system’s component, we can establish the Data Lake to ingest and persist data in any format and subsequently process to meet our requirement. Industries have started adopting Hadoop for its massively parallel storage and parallel processing in a distributed manner. On top of it, Hadoop is an open source framework which can be customized as per our need. Companies like MapR, Hortonworks, Cloudera have done enough customization in specific areas of Hadoop framework and released their own version of Hadoop into the market. By effective utilization of Hadoop Distributed File System (HDFS), we can establish Data Lake irrespective of data format. In HDFS, data are stored in a distributed manner. By installing Hadoop (HDFS) in a horizontal cluster, we can eliminate data storage scarcity which is a major concern on traditional data storage systems, Warehouse etc. In case infrastructure for cluster setup a major concern, we can leverage cloud computing. For example Amazon web service (AWS)’s EC2 instances can be used to create multiple nodes for the cluster with configurable resources. Now we need to configure two component namely Apache Flume and Sqoop with HDFS. Flume and Sqoop are the two component belongs to Hadoop ecosystem and are responsible for ingesting data into HDFS. Using Flume, we can ingest streaming data like server log, data from social media like Twitter etc into HDFS. With Sqoop, we can transfer data from the RDBMS into HDFS and similarly from HDFS to RDBMS. With the above components, semi-structured data mainly from social media and tubular form data (row column) from RDBMS can be ingested to the Data Lake which is nothing but HDFS. Eventually, for unstructured data like Blog, email etc, we have to develop data pipeline through which required data can be ingested into the HDFS. Prior to that, all the required unstructured data should be dumped into HDFS. Since HDFS is a distributed file system, there is a constraint to dump any format of data into HDFS. Map Reduce programming or Spark can be used to convert dumped unstructured data into the desired form so that it can be blended with other ingested data inside Lake for analysis and finding out the appropriate depth.