19Dec
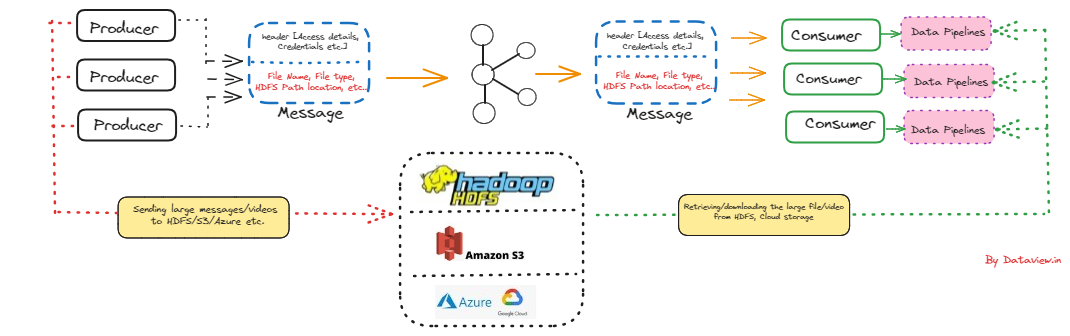
Architecture to leverage Apache Kafka for sharing large messages (GB size)
In today's data-driven world, the capability to transport and circulate large amounts of data, especially video files, in real-time is crucial for news media companies. For example, an incident occurred in a specific location, and a news reporter promptly filmed the entire situation. Subsequently, the complete video was distributed for broadcasting across their multiple studios situated in geographically distant locations. To construct or create a comprehensive solution for the given problem statement, we can utilize Apache Kafka in conjunction with...